最近对于进程和线程之间的关系及其本质有所疑惑,在网上查询了多个答案之后有了些感想,记录下
多任务
现代操作系统比如Mac OS X,UNIX,Linux,Windows等,都是支持“多任务”的操作系统。
什么叫“多任务”呢?简单地说,就是操作系统可以同时运行多个任务。打个比方,你一边在用浏览器上网,一边在听MP3,一边在用Word赶作业,这就是多任务,至少同时有3个任务正在运行。还有很多任务悄悄地在后台同时运行着,只是桌面上没有显示而已。
现在,多核CPU已经非常普及了,但是,即使过去的单核CPU,也可以执行多任务。由于CPU执行代码都是顺序执行的,那么,单核CPU是怎么执行多任务的呢?
答案就是操作系统轮流让各个任务交替执行,任务1执行0.01秒,切换到任务2,任务2执行0.01秒,再切换到任务3,执行0.01秒……这样反复执行下去。表面上看,每个任务都是交替执行的,但是,由于CPU的执行速度实在是太快了,我们感觉就像所有任务都在同时执行一样。
真正的并行执行多任务只能在多核CPU上实现,但是,由于任务数量远远多于CPU的核心数量,所以,操作系统也会自动把很多任务轮流调度到每个核心上执行。
进程的概念
对于操作系统来说,一个任务就是一个进程(Process),比如打开一个浏览器就是启动一个浏览器进程,打开一个记事本就启动了一个记事本进程,打开两个记事本就启动了两个记事本进程,打开一个Word就启动了一个Word进程。
进程的本质
cpu的单次运算
线程的概念
有些进程还不止同时干一件事,比如Word,它可以同时进行打字、拼写检查、打印等事情。在一个进程内部,要同时干多件事,就需要同时运行多个“子任务”,我们把进程内的这些“子任务”称为线程(Thread)。
线程的本质
由于每个进程至少要干一件事,所以,一个进程至少有一个线程。当然,像Word这种复杂的进程可以有多个线程,多个线程可以同时执行,多线程的执行方式和多进程是一样的,也是由操作系统在多个线程之间快速切换,让每个线程都短暂地交替运行,看起来就像同时执行一样。当然,真正地同时执行多线程需要多核CPU才可能实现。
线程的特点
由于同一进程的多个线程共享同一地址空间,因此Text Segment、Data Segment都是共享的,如果定义一个函数,在各线程中都可以调用,如果定义一个全局变量,在各线程中都可以访问到,除此之外,各线程还共享以下进程资源和环境:
文件描述符表
每种信号的处理方式(SIG_IGN、SIG_DFL或者自定义的信号处理函数)
当前工作目录
用户id和组id
但有些资源是每个线程各有一份的:
线程id
上下文,包括各种寄存器的值、程序计数器和栈指针
栈空间
errno变量
信号屏蔽字
调度优先级
进程的通信
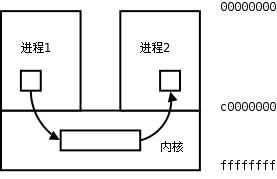
每个进程各自有不同的用户地址空间,任何一个进程的全局变量在另一个进程中都看不到,所以进程之间要交换数据必须通过内核,在内核中开辟一块缓冲区,进程1把数据从用户空间拷到内核缓冲区,进程2再从内核缓冲区把数据读走,内核提供的这种机制称为进程间通信(IPC,InterProcess Communication)。如下图所示。
图 30.6. 进程间通信
进程间通信
管道
管道是一种最基本的IPC机制,由pipe函数创建:1
2
int pipe(int filedes[2]);
调用pipe函数时在内核中开辟一块缓冲区(称为管道)用于通信,它有一个读端一个写端,然后通过filedes参数传出给用户程序两个文件描述符,filedes[0]指向管道的读端,filedes[1]指向管道的写端(很好记,就像0是标准输入1是标准输出一样)。所以管道在用户程序看起来就像一个打开的文件,通过read(filedes[0]);或者write(filedes[1]);向这个文件读写数据其实是在读写内核缓冲区。pipe函数调用成功返回0,调用失败返回-1。
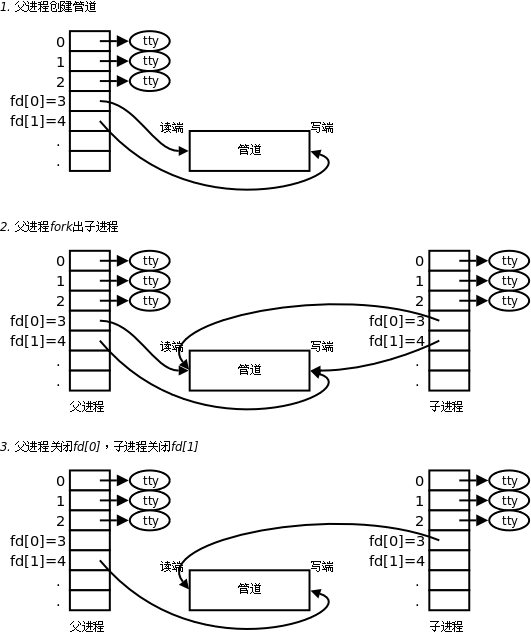
开辟了管道之后如何实现两个进程间的通信呢?比如可以按下面的步骤通信。
1.父进程调用pipe开辟管道,得到两个文件描述符指向管道的两端。
2.父进程调用fork创建子进程,那么子进程也有两个文件描述符指向同一管道。
3.父进程关闭管道读端,子进程关闭管道写端。父进程可以往管道里写,子进程可以从管道里读,管道是用环形队列实现的,数据从写端流入从读端流出,这样就实现了进程间通信。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
int main(void)
{
int n;
int fd[2];
pid_t pid;
char line[MAXLINE];
if (pipe(fd) < 0) {
perror("pipe");
exit(1);
}
if ((pid = fork()) < 0) {
perror("fork");
exit(1);
}
if (pid > 0) { /* parent */
close(fd[0]);
write(fd[1], "hello world\n", 12);
wait(NULL);
} else { /* child */
close(fd[1]);
n = read(fd[0], line, MAXLINE);
write(STDOUT_FILENO, line, n);
}
}
使用管道有一些限制:
两个进程通过一个管道只能实现单向通信,比如上面的例子,父进程写子进程读,如果有时候也需要子进程写父进程读,就必须另开一个管道。请读者思考,如果只开一个管道,但是父进程不关闭读端,子进程也不关闭写端,双方都有读端和写端,为什么不能实现双向通信?
管道的读写端通过打开的文件描述符来传递,因此要通信的两个进程必须从它们的公共祖先那里继承管道文件描述符。上面的例子是父进程把文件描述符传给子进程之后父子进程之间通信,也可以父进程fork两次,把文件描述符传给两个子进程,然后两个子进程之间通信,总之需要通过fork传递文件描述符使两个进程都能访问同一管道,它们才能通信。
使用管道需要注意以下4种特殊情况(假设都是阻塞I/O操作,没有设置O_NONBLOCK标志):
如果所有指向管道写端的文件描述符都关闭了(管道写端的引用计数等于0),而仍然有进程从管道的读端读数据,那么管道中剩余的数据都被读取后,再次read会返回0,就像读到文件末尾一样。
如果有指向管道写端的文件描述符没关闭(管道写端的引用计数大于0),而持有管道写端的进程也没有向管道中写数据,这时有进程从管道读端读数据,那么管道中剩余的数据都被读取后,再次read会阻塞,直到管道中有数据可读了才读取数据并返回。
如果所有指向管道读端的文件描述符都关闭了(管道读端的引用计数等于0),这时有进程向管道的写端write,那么该进程会收到信号SIGPIPE,通常会导致进程异常终止。在第 33 章 信号会讲到怎样使SIGPIPE信号不终止进程。
如果有指向管道读端的文件描述符没关闭(管道读端的引用计数大于0),而持有管道读端的进程也没有从管道中读数据,这时有进程向管道写端写数据,那么在管道被写满时再次write会阻塞,直到管道中有空位置了才写入数据并返回。
现在把进程之间传递信息的各种途径(包括各种IPC机制)总结如下:
-父进程通过fork可以将打开文件的描述符传递给子进程
-子进程结束时,父进程调用wait可以得到子进程的终止信息
-几个进程可以在文件系统中读写某个共享文件,也可以通过给文件加锁来实现进程间同步
-进程之间互发信号,一般使用SIGUSR1和SIGUSR2实现用户自定义功能
-管道
-FIFO
-mmap函数,几个进程可以映射同一内存区
-SYS V IPC,以前的SYS V UNIX系统实现的IPC机制,包括消息队列、信号量和共享内存,现在已经基本废弃
-UNIX Domain Socket,目前最广泛使用的IPC机制
线程的通信
多个线程同时访问共享数据时可能会冲突,线程中的内存是共享的,导致所处理的变量是同一个,比如两个线程都要把某个全局变量增加1,这个操作在某平台需要三条指令完成:
1.从内存读变量值到寄存器
2.寄存器的值加1
3.将寄存器的值写回内存
假设两个线程在多处理器平台上同时执行这三条指令,则可能导致下图所示的结果,最后变量只加了一次而非两次。

对于多线程的程序,访问冲突的问题是很普遍的,解决的办法是引入互斥锁(Mutex,Mutual Exclusive Lock),获得锁的线程可以完成“读-修改-写”的操作,然后释放锁给其它线程,没有获得锁的线程只能等待而不能访问共享数据,这样“读-修改-写”三步操作组成一个原子操作,要么都执行,要么都不执行,不会执行到中间被打断,也不会在其它处理器上并行做这个操作。
pthread_mutex_init函数对Mutex做初始化,参数attr设定Mutex的属性,如果attr为NULL则表示缺省属性,本章不详细介绍Mutex属性,感兴趣的读者可以参考[APUE2e]。用pthread_mutex_init函数初始化的Mutex可以用pthread_mutex_destroy销毁。如果Mutex变量是静态分配的(全局变量或static变量),也可以用宏定义PTHREAD_MUTEX_INITIALIZER来初始化,相当于用pthread_mutex_init初始化并且attr参数为NULL。Mutex的加锁和解锁操作可以用下列函数:1
2
3
4
5
int pthread_mutex_lock(pthread_mutex_t *mutex);
int pthread_mutex_trylock(pthread_mutex_t *mutex);
int pthread_mutex_unlock(pthread_mutex_t *mutex);
返回值:成功返回0,失败返回错误号。
一个线程可以调用pthread_mutex_lock获得Mutex,如果这时另一个线程已经调用pthread_mutex_lock获得了该Mutex,则当前线程需要挂起等待,直到另一个线程调用pthread_mutex_unlock释放Mutex,当前线程被唤醒,才能获得该Mutex并继续执行。
如果一个线程既想获得锁,又不想挂起等待,可以调用pthread_mutex_trylock,如果Mutex已经被另一个线程获得,这个函数会失败返回EBUSY,而不会使线程挂起等待。
Mutex的两个基本操作lock和unlock是如何实现的呢?假设Mutex变量的值为1表示互斥锁空闲,这时某个进程调用lock可以获得锁,而Mutex的值为0表示互斥锁已经被某个线程获得,其它线程再调用lock只能挂起等待。那么lock和unlock的伪代码如下:
lock:1
2
3
4
5
6
7
8
9
10
11if(mutex > 0){
mutex = 0;
return 0;
} else
//挂起等待;
goto lock;
unlock:
mutex = 1;
//唤醒等待Mutex的线程;
return 0;
unlock操作中唤醒等待线程的步骤可以有不同的实现,可以只唤醒一个等待线程,也可以唤醒所有等待该Mutex的线程,然后让被唤醒的这些线程去竞争获得这个Mutex,竞争失败的线程继续挂起等待。
死锁
1.一般情况下,如果同一个线程先后两次调用lock,在第二次调用时,由于锁已经被占用,该线程会挂起等待别的线程释放锁,然而锁正是被自己占用着的,该线程又被挂起而没有机会释放锁,因此就永远处于挂起等待状态了,这叫做死锁(Deadlock)。
2.另一种典型的死锁情形是这样:线程A获得了锁1,线程B获得了锁2,这时线程A调用lock试图获得锁2,结果是需要挂起等待线程B释放锁2,而这时线程B也调用lock试图获得锁1,结果是需要挂起等待线程A释放锁1,于是线程A和B都永远处于挂起状态了。不难想象,如果涉及到更多的线程和更多的锁,有没有可能死锁的问题将会变得复杂和难以判断。